








W poprzedniej części bloga dowiedzieliśmy się, jak w programie SDL Trados Studio rozdzielić jednostki z dużego plik sdlxliff między kilku tłumaczy, a następnie przerzucić cząstkowe tłumaczenia do jednego pliku, uzyskując w ten sposób jeden przetłumaczony w całości dokument. Ta metoda dzielenia dużego pliku opiera się na funkcji PerfectMatch, która jednak jest dostępna tylko w wersji Professional. Co zrobić, jeśli mamy jedynie wersję Freelance? W tej części dowiemy się, jak uzyskać podobny efekt bez użycia funkcji PerfectMatch.
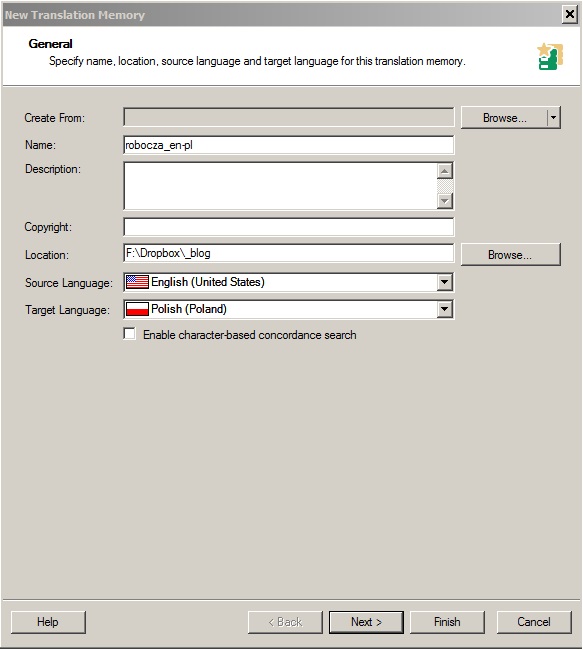
Na początku tworzymy roboczą pamięć tłumaczeń , w naszym przykładzie jest to pamięć robocza_en-pl:
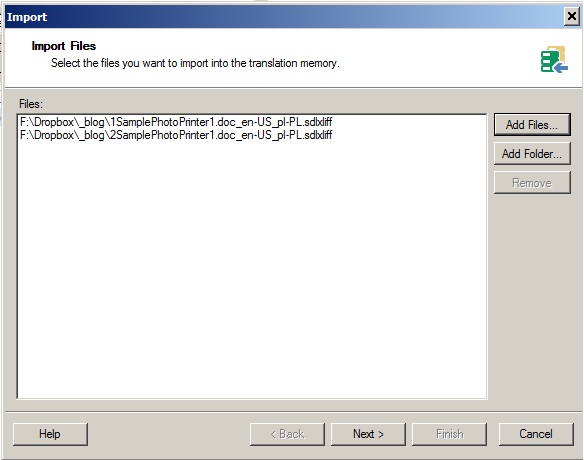
Następnie importujemy do niej wszystkie jednostki z przetłumaczonych plików cząstkowych (plików 1_ SamplePhotoPrinter.doc.sdlxliff oraz 2_ SamplePhotoPrinter.doc.sdlxliff – zob. część 1):
Teraz otwieramy nasz oryginalny plik sdlxliff i wybieramy widok Files. Klikamy prawym przyciskiem myszy nazwę pliku, a następnie wybieramy kolejno opcje Batch Tasks i Pre-Translate Files. W oknie Batch Tasks klikamy przycisk Next. W oknie Settings klikamy opcję Translation Memory and Automated Translation, a następnie dodajemy naszą roboczą pamięć tłumaczeń.
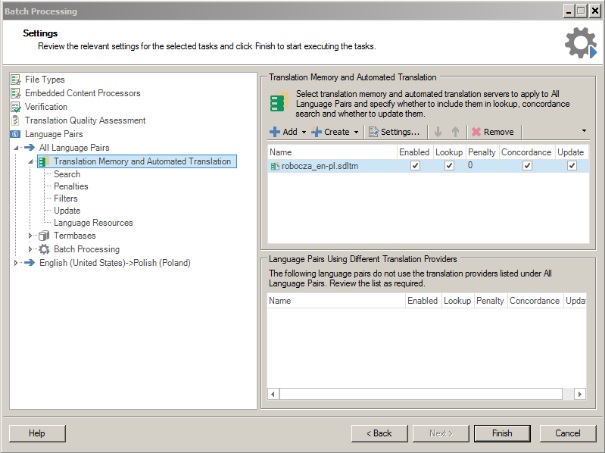
Klikamy kolejno przyciski Finish i Close. W oknie Question klikamy przycisk Tak. Przetłumaczony plik zostanie otwarty w edytorze Studio.
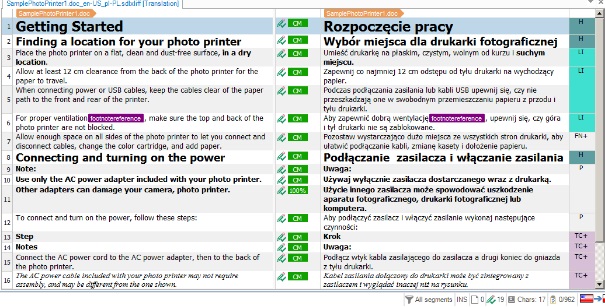
Widzimy, że prawie wszystkie jednostki mają status ContextMatch. Jak pamiętamy, w metodzie opisanej w części pierwszej jednostki pliku wynikowego miały status PerfectMatch. Na czym polega różnica?
W celu zapewnienia maksymalnej zgodności kontekstowej funkcja PerfectMatch sprawdza zarówno poprzedni, jak i następny segment tekstu. Tłumaczenie bieżącego segmentu jest wstawiane, jeśli w dokumencie, z którego pochodzi tłumaczenie, oba segmenty — poprzedni i następny — są identyczne jak w bieżącym dokumencie. Funkcja ContextMatch bazuje zaś na informacjach zapisanych w pamięci tłumaczeń , gdzie dla danego segmentu jest przechowywana informacja o segmencie poprzedzającym. Wstawione z pamięci tłumaczeń tłumaczenie segmentu uzyskuje status ContextMatch, jeśli poprzedni segment w dokumencie, z którego tłumaczenie zostało wstawione do pamięci tłumaczeń, jest identyczny jak w bieżącym dokumencie. Jeśli chodzi o pierwszy segment w dokumencie (gdy nie ma segmentu poprzedzającego), pod uwagę brane są inne informacje, na przykład to, że pierwszy segment jest nagłówkiem dokumentu.
W naszym przykładowym dokumencie segment nr 11 ma status 100%. Jest to spowodowane tym, że pierwotnie przetłumaczony segment był pierwszym segmentem drugiego pliku tłumaczeń cząstkowych, a więc poprzedzający go segment (nr 10) był pusty:

Dla pewności warto zatem sprawdzić poprawność segmentów o statusie 100% (występują one w miejscach dzielenia pierwotnego pliku).
Opisane metody można również wykorzystać do „uratowania” uszkodzonego pliku sdlxliff, z którego nie można wygenerować pliku wynikowego. Ale o tym w kolejnym wpisie.

