








Zdarza się ta idealna sytuacja, gdy otrzymujemy do tłumaczenia bardzo duży plik sdlxliff i wystarczająco dużo czasu, aby plik mógł zostać obsłużony przez jednego tłumacza. Z reguły jednak termin jest krótki i nie pozostaje nam nic innego, jak podzielić pracę na dwie lub więcej osób. Możemy wtedy skorzystać z SDL XLIFF Split/Merge — rozwiązania, które pozwala podzielić plik sdlxliff na kilka mniejszych. To pomocne narzędzie ma jednak pewne ograniczenia. Po pierwsze czasem pojawiają się problemy z połączeniem plików z powrotem w jeden plik sdlxliff. Po drugie tłumacz nie ma możliwości zapisania pliku docelowego z takiego podzielonego pliku sdlxliff, przez co nie może na przykład sprawdzić podglądu przetłumaczonego pliku.
Aby zaradzić tym problemom, można skorzystać z alternatywnego rozwiązania. Jest ono względnie proste i nie wymaga użycia żadnych dodatkowych narzędzi. Polega na podzieleniu pracy przez wydzielenie jednostek przeznaczonych do przetłumaczenia przez jedną osobę w całym pliku, a następnie przerzucenie cząstkowych tłumaczeń do jednego, ostatecznego pliku.
Dla przykładu weźmy plik, który ma 19 segmentów i razem 219 słów:
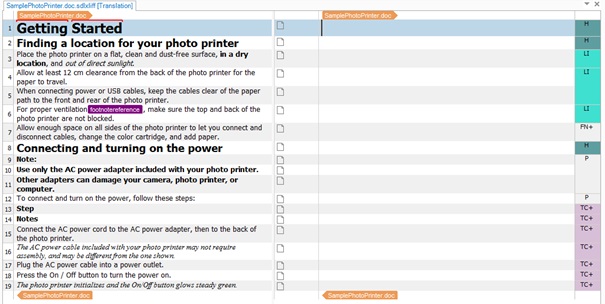
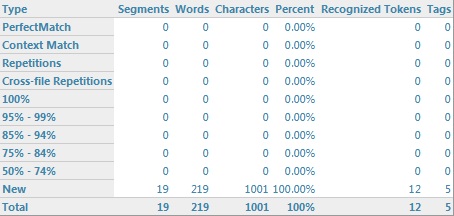
Załóżmy, że chcemy podzielić pracę nad tym plikiem między dwóch tłumaczy: jeden ma się zająć jednostkami od 1 do 10, a drugi — jednostkami od 11 do 19. Tworzymy dwie kopie oryginalnego pliku SamplePhotoPrinter.doc.sdlxliff:
1_ SamplePhotoPrinter.doc.sdlxliff oraz 2_ SamplePhotoPrinter.doc.sdlxliff. Następnie otwieramy pierwszy plik w edytorze SDL Trados Studio i blokujemy jednostki od 11 do 19 (opcja Lock Segments).
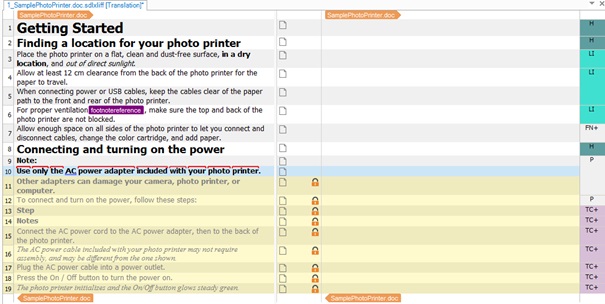
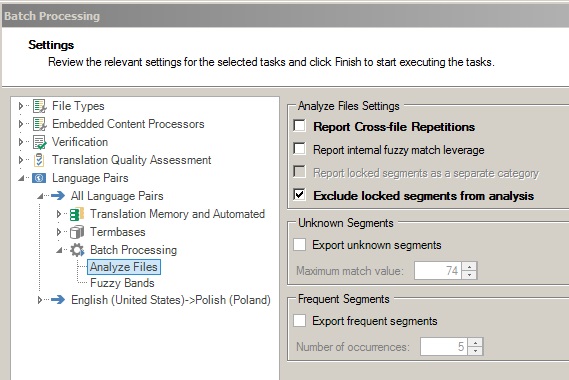
Podobnie robimy z drugim plikiem: otwieramy go, ale tym razem blokujemy jednostki od 1 do 10. Możemy teraz wykonać analizę tych plików, zaznaczając opcję Exclude locked segments from analysis (Studio 2015) w oknie Batch Processing -> Settings -> Analyze Files:
Wyniki analizy wyglądają następująco:
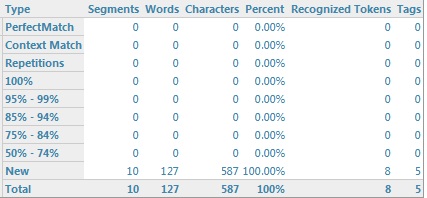
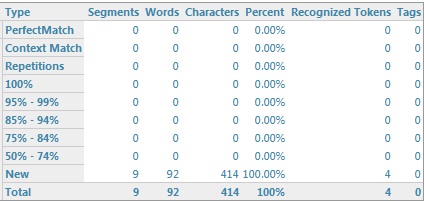
W wersji Studio 2014 nie ma opcji Exclude locked segments from analysis, ale podobny efekt możemy uzyskać, zaznaczając opcję Report locked segments as separate category. Wtedy wyniki analizy będą wyglądać następująco:
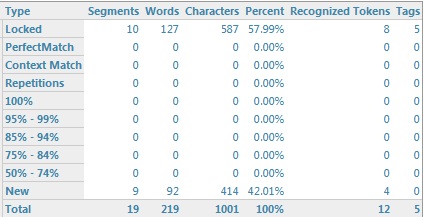
W obu przypadkach umożliwi to nam prawidłowe wyliczenie liczby słów do przetłumaczenia w poszczególnych plikach. Studio 2011 nie oferuje niestety żadnej z tych opcji, dlatego w wersji tej nie ma prostego sposobu wykonania analizy pliku z wykluczeniem zablokowanych jednostek.
Tak przygotowane pliki przekazujemy do tłumaczenia. Gdy pliki są już przetłumaczone, otwieramy je i odblokowujemy zablokowane jednostki. Następnie otwieramy nasz oryginalny pliku sdlxliff, wybieramy widok Files, klikamy prawym przyciskiem myszy nazwę pliku, a następnie wybieramy kolejno opcje Batch Tasks i Apply PerfectMatch. W oknie Batch Tasks klikamy przycisk Next, a w oknie SDL Perfect Match dodajemy pierwszy z przetłumaczonych plików jako Previous Document.
Aby w ostatecznym pliku zachować statusy z przetłumaczonych plików, wybieramy opcję Use the original translation origin and status.
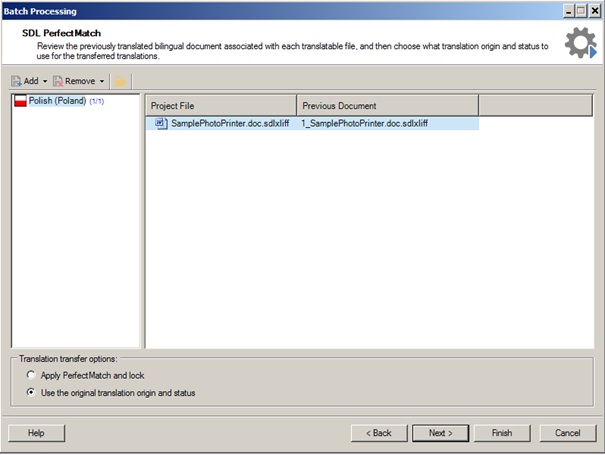
Klikamy kolejno przyciski Finish i Close.
Po otwarciu w edytorze plik wygląda teraz następująco:
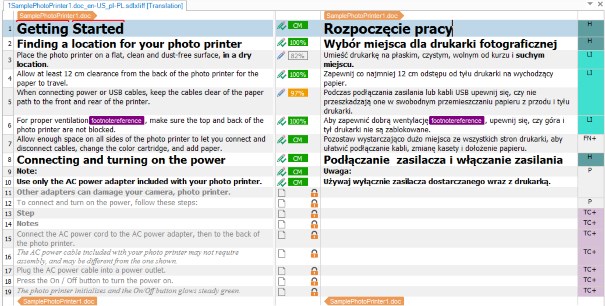
Przechodzimy ponownie do widoku Files i powtarzamy całą procedurę, tym razem wybierając drugi plik jako Previous Document. Po wykonaniu procedury dla wszystkich plików częściowych (w tym przykładzie dwóch) otrzymujemy wynikowy dokument:
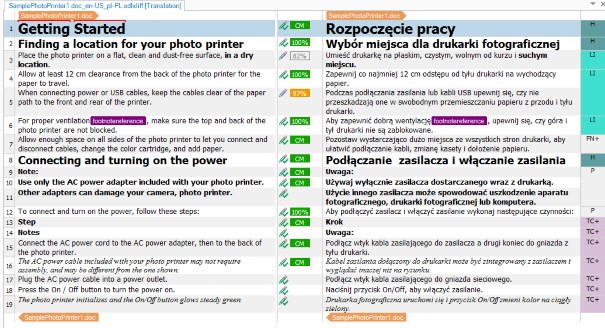
Jeśli w oknie SDL Perfect Match wybierzemy opcję Apply PerfectMatch and lock, to nie musimy odblokowywać wcześniej zablokowanych jednostek w plikach częściowych. Wszystkie jednostki pliku wynikowego będą zablokowane ze statusem PerfectMatch:
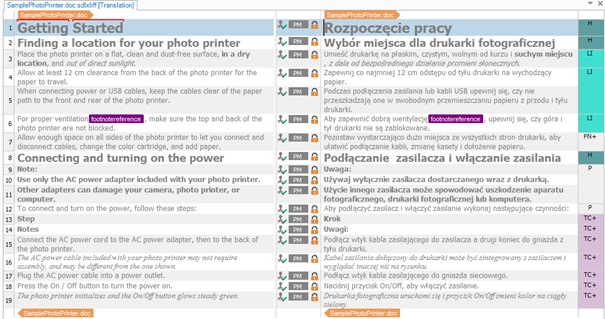
A co zrobić, jeśli mamy tylko wersję Freelance, w której nie ma funkcji PerfectMatch? O tym w drugiej części artykułu już wkrótce!

